
What we did
The concept of data governance exists in different forms, it has varied purposes and requires different institutions in order to work. At Mozfest 2022, we explored what a notion of data governance could take from a data justice perspective. This included examining how people were represented in governance frameworks, how they could participate, and what their capacities were to address harms caused to them.
As a starting point for the workshop, we aimed to collect ideas, phrases and keywords of how the participants at the workshop understood data governance. This was to establish whether we all had a common sense of the concept, and also at what points we disagreed. To do this, we used an online collaborative tool called Miro and shared through silent brainstorming facets of what data governance does, where it takes place, how it works, and why it matters. This approach allowed us to collect a variety of responses, and also points of departure.
With a group of around 12 participants, our next step was to find ways to cluster the different ideas based on how they related to each other, and how similar they were. Through this clustering, we found views coming together around institutions that contribute to data governance, the role of collectives and groups in influencing data governance, structural inequalities that underpin a data economy and more conceptual questions around trust in data governance.
Having established a baseline for discussion, the next part of the workshop took on a speculative dimension from where we wanted the group to imagine alternative futures for data governance. We introduced the following generative obstacles and asked the group to imagine how overcoming these could help shape different visions for data governance.
1. Selling data is impossible.
2. Communities control all of their own data (including data about them such as mobile phone metadata, inferences and profiles), with appropriate governance structures throughout the system to allow them to have a veto on any activities that involve data about them.
3. Everything is open data unless it is person-specific health or banking records.
4. People must be paid market value for the use of any data about them, throughout its lifecycle
What it produced
Conducting the workshop surfaced several problems we found interesting. First, on the Global Data Justice project, we work with a broad notion of data governance, going beyond how you handle data in compliance with the law. But this turned out not to be an intuitive concept, even for people who work on ‘data governance’ directly. The political economy element is seldom there in analyses of data governance, and when we start from questions about aims, incentives and institutions, people rapidly lose their familiar reference points and become a bit alienated.
This meant that each time we tried to pin ‘data governance’ down (‘write down some keywords and concepts about data governance as you see it… cluster those keywords and concepts’), it receded from view. Lesson: we should think about the outputs of data governance (‘trust’, ‘control’, ‘coordination’) separately from the inputs (‘stewardship arrangements’, ‘data protection’), and from the surrounding context (‘global power inequalities, political economy of institutions’). From one participant: ‘Data governance is not just governance, it’s many things… justice is definitely one of them.’
It also proved challenging to do this exercise with a diverse group who did not know each other: without a shared definition of governance, it was difficult to isolate the components we care about. We did manage to form clusters out of our diverse understandings (see image below) – one about power and control (1); one about intersecting interests (2); one about actors (3) and another about the process (4). These obstinately continued to overlap, however – the ‘should’ and the ‘is’ seem very hard to separate when we discuss data governance.
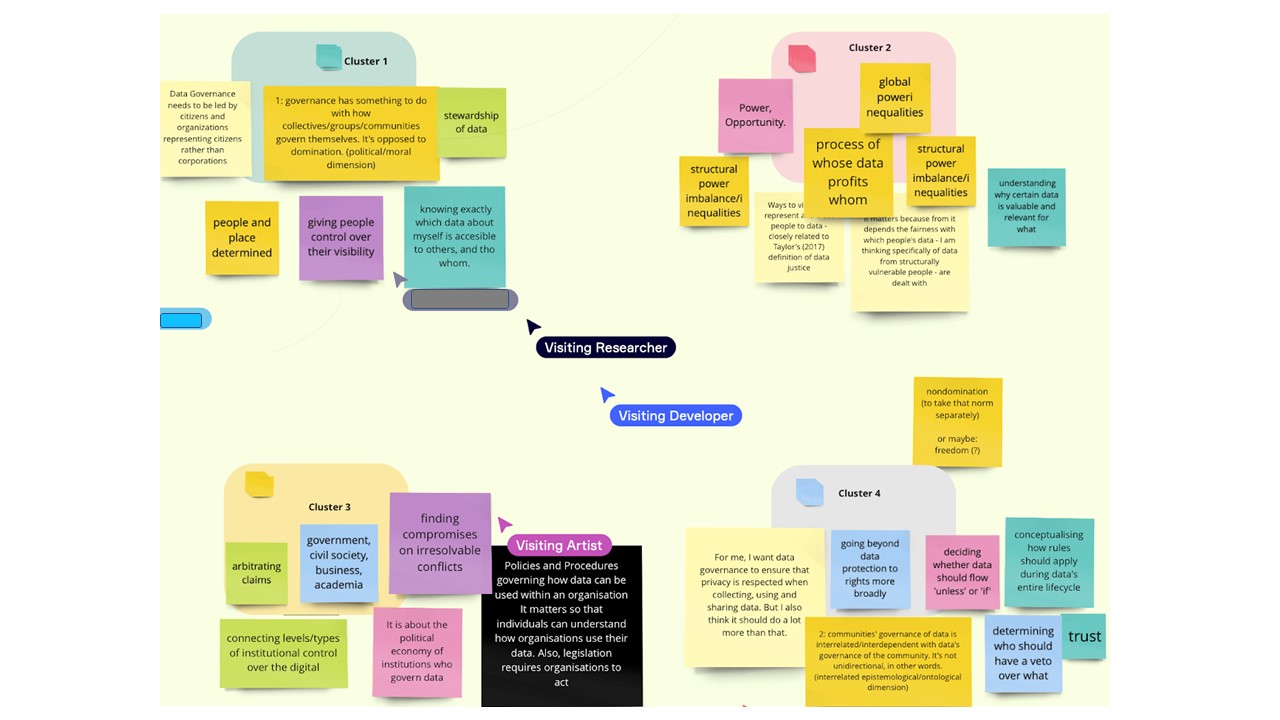
Our exercise involving the large-scale disruptive obstacles to business-as-usual, as listed above, proved fairly coherent. We had three groups choose the obstacle ‘Communities control all of their own data’. Out of their discussion came the following ideas:
- It’s not clear how we should define a ‘community’, and how communities’ control over data would overlap in practice.
- The burden of work in terms of making one’s group visible in data governance would be huge for marginalised communities and would require funded data management organisations and ethics review boards.
- We would need peer-to-peer governance mechanisms for data sharing, and some communities might choose not to share, for example, public health data, creating public goods problems. This would lead to individuals being leveraged to share data for public governance purposes. Marginalisation might cause polarisation, and the ability to share and use data would be differentiated among communities according to resources.
- Community control would create issues of responsibility, accountability and transparency, although it probably increases trust in data governance because the data lifecycle would be determined by the community.
- There would be concerns about democratic process: preserving the individual freedom to veto uses of data would become an issue; election mechanisms and oversight structures would become necessary to govern data on this smaller scale.
There was one group which chose the obstacle that people must be paid for the use of data about them. This group’s discussions resulted in these insights:
- oppressive uses of data such as predictive policing would be changed by this requirement because public authorities would not be able to simply define data as public, but would have to negotiate with individuals for data that reflected their behaviour, movement or identities
- Monetary compensation for digital labour might be a double-edged sword because it would leave minority groups – who often are financially disadvantaged – more vulnerable to exploitation.
- Our current digital economies would collapse because they rely on ‘free’ data – at least if this idea were carried out fully, about all sorts of data, rather than the most conveniently portable, mainly commercial, data types as currently conceptualised in many alternate visions of personal data ownership.
What we learned
When a group of people from different backgrounds try to pin down what data governance is, the answers vary across the board. Some participants identified the actors governing (e.g. government/civil society/academia/ business), others focused on the processes by which these actors govern (e.g. policies and procedures, legislation, arbitrating claims), and some emphasized which terms these processes take place (e.g who is included/excluded / need to be led by citizens rather than corporations / how people’s data is dealt with, especially the most structurally vulnerable). It was challenging to answer with a unified conceptualization of what we want data governance to achieve. Participants had an easier time conceptualizing harms, specific data technologies and applications, and particular rights that pertain to data rather than thinking normatively about data governance per se – what kind of power gets balanced and arbitrated when we do it. In a sense, thinking about data governance is more reactive than proactive. It is a response to specific cases.
The speculative obstacles were challenging this way of thinking. These scenarios pushed the group to collectively and creatively contemplate what happens when data justice is pushed to its logical extremes. Once again, the participants focused on the emergence of new actors and the importance of accounting for the marginalized. By thinking about ways in which data governance breaks, we could begin to distil, based on the direction of these answers, what the participants expected data governance to achieve.
Despite the diversity in thinking about data governance, one key issue kept resurfacing; that is the current rhetoric surrounding data governance. It is often framed in terms of economics or privacy, and this is insufficient. One participant said: ‘there is a political dimension to it focusing on individuals and privacy doesn’t do justice – in attempts to govern data there is an interaction between what you are trying to govern and how it affects the governor.’
